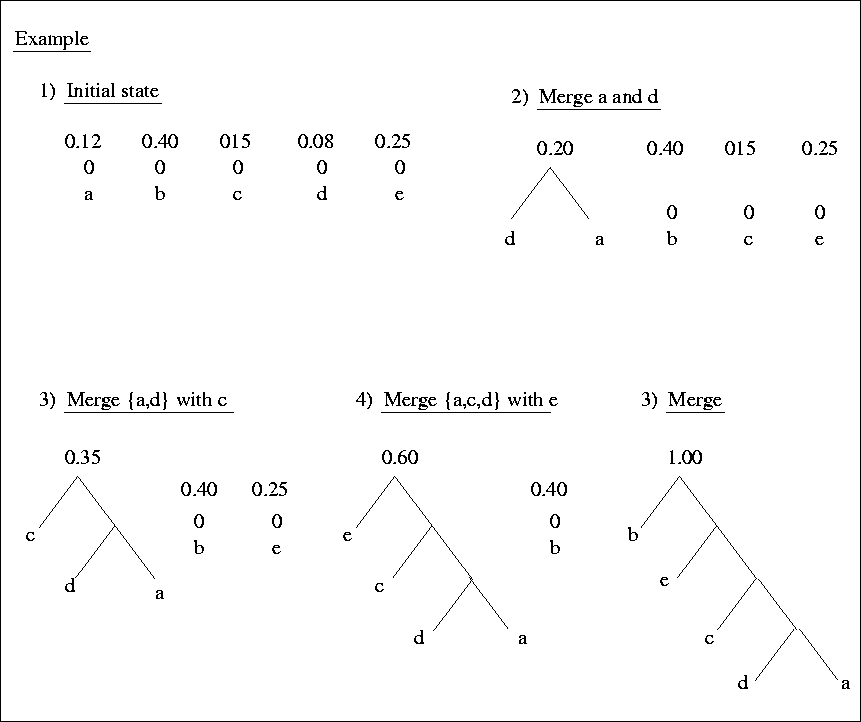
e.g. - Suppose we have a message made from the five characters a,
b, c, d, e, with probabilities 0.12, 0.40, 0.15, 0.08, 0.25, respectively.
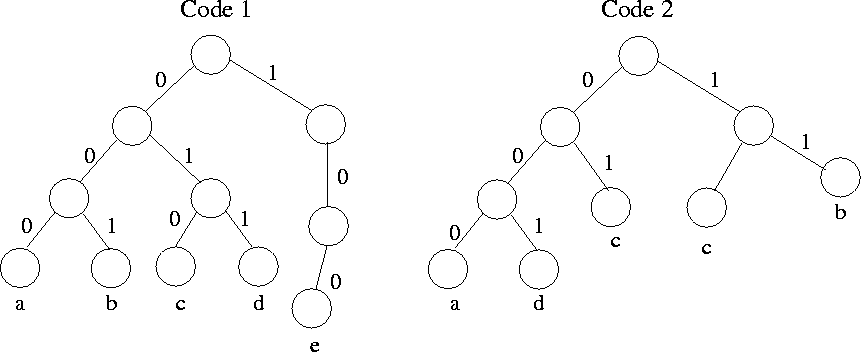
We wish to encode each character into a sequence of 0s and 1s so that no code for a character is the prefix of the code for any other character. This prefix property allows us to decode a string of 0s and 1s by repeatedly deleting prefixes of the string that are codes for characters.
Symbol Prob code 1 code 2 a 0.12 000 000 b 0.40 001 11 c 0.15 010 01 d 0.08 011 001 e 0.25 100 10In the above, Code 1 has the prefix property. Code 2 also has the prefix property.
 |
 |