Two main issues:
If x1 and x2 are two different keys, it is possible that h(x1) = h(x2). This is called a collision. Collision resolution is the most important issue in hash table implementations.
Choosing a hash function that minimizes the number of collisions and also hashes uniformly is another critical issue.
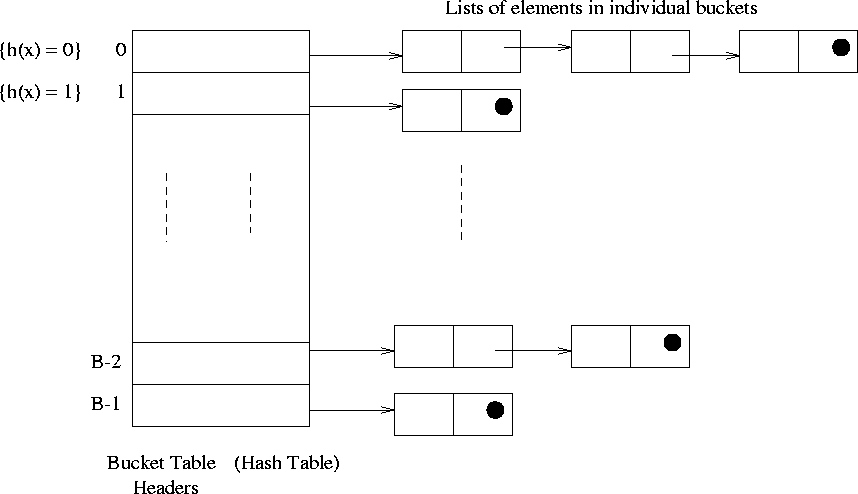
Collision Resolution by Chaining
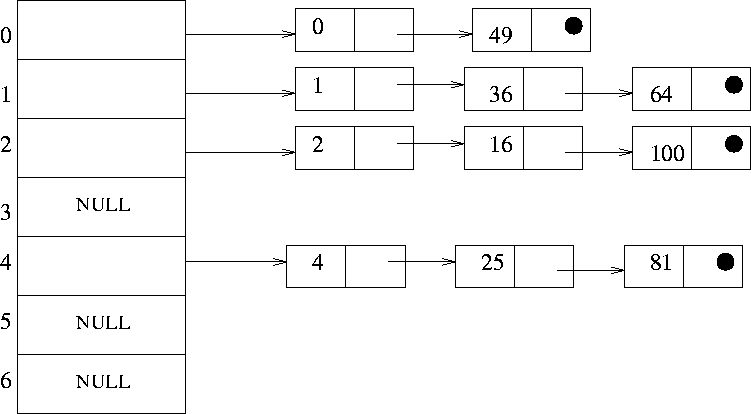
Example:
See Figure 3.2. Consider the keys 0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100. Let the hash function be:
Insert x at the head of list T[h(key (x))]
Search for an element x in the list T[h(key (x))]
Delete x from the list T[h(key (x))]
Worst case complexity of all these operations is O(n)
In the average case, the running time is O(1 + ![]() ),
where
),
where
| = | load factor |
(3.1) | |
| n | = | number of elements stored | (3.2) |
| m | = | number of hash values or buckets |
It is assumed that the hash value h(k) can be computed in O(1) time. If n is O(m), the average case complexity of these operations becomes O(1) !